Megatron 训练
前置知识
一元函数链式法则
若,并且,那么:
多元函数链式法则
若,并且,那么:
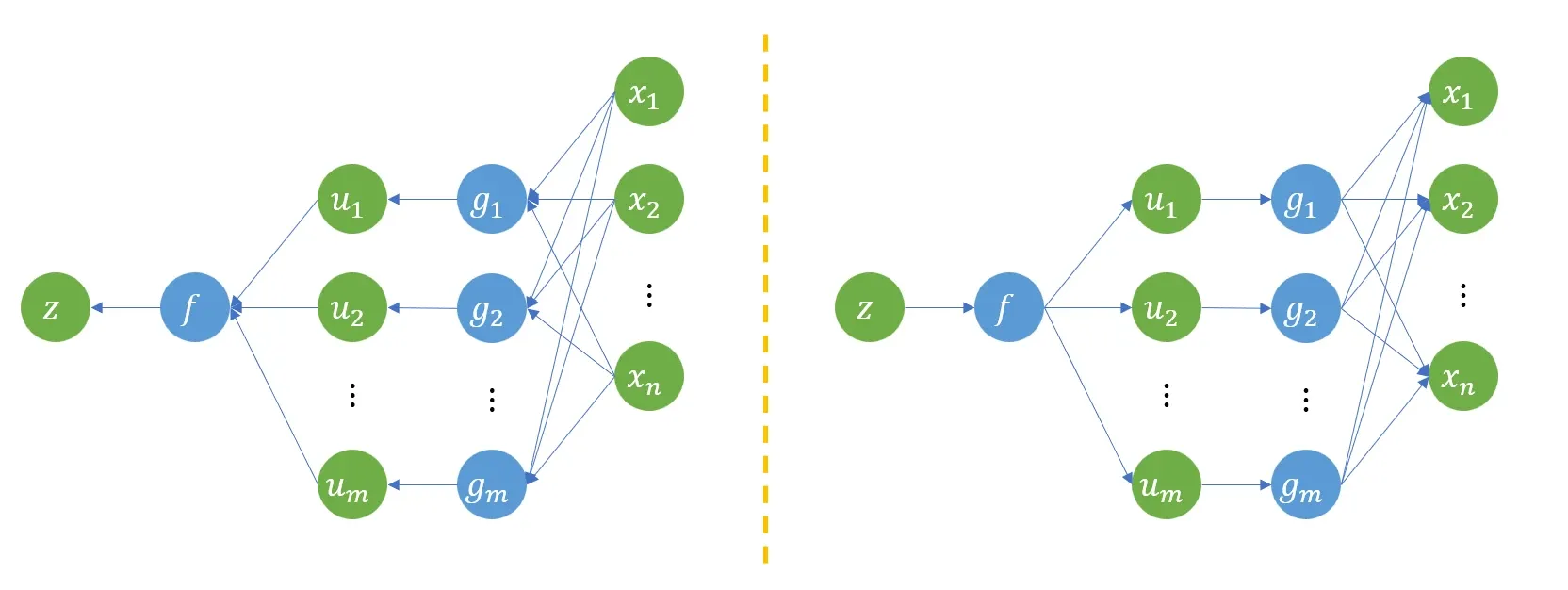
可以发现前向过程是一个非线性过程(神经网络),而反向过程是一个线性过程(梯度更新)。 这也就解释了为什么分batch、micro-batch、mini-batch可以被线性合并。
多元函数梯度计算
对于一个多元标量函数,其梯度的定义为:
对于多元向量函数运算,关于的导数可以用一阶导数Jacobian矩阵表示:
一般情况下,模型最终会求得一个标量损失,假设我们已经求得了关于的导数:
根据链式法则,那么关于的导数为:
举个例子,例如第一行:
另外,二阶导数Hessian矩阵表示:
一般网络剪枝、GPTQ等会计算二阶导数Hessian矩阵评估一个参数的重要程度或者最优化目标,这里就不详细展开了。
Pytorch的自动求导与动态计算图
可以发现在反向传播梯度的过程中,本质上就是按拓扑序计算一个DAG图,这个DAG图被称为计算图,是前向计算构造的。 于是Pytorch利用这个特性就可以实现自动求导,首先Pytorch在用户前向计算的过程中,会动态构造计算图。
一个计算图的组成通常是:
- 节点:一个可导计算被Pytorch创建一个节点,被该计算节点的输出变量引用,在Pytorch中可以调用变量的
grad_fn属性获得其关联的节点。 - 边:计算节点和计算节点之间的连接,对一个计算节点来说,一个输入变量就会创建一条边。边信息存储为一个元祖列表[(第1个输入变量关联的节点, 第1个输入变量是其关联的节点的第几个输出), …]。可以通过
grad_fn属性上的next_functions属性查看一个节点的边。
举个例子:
x = torch.randn(16, requires_grad= True)
y = torch.randn(16, requires_grad= True)
z = x + y
l = z.sum()
print(l.grad_fn) # <SumBackward0 object at 0x7cf2f118c550>
print(l.grad_fn.next_functions) # ((<AddBackward0 object at 0x7cf2f118c520>, 0),)
print(z.grad_fn.next_functions) # ((<AccumulateGrad object at 0x7cf2f118c550>, 0), (<AccumulateGrad object at 0x7cf2f118cdc0>, 0))
print(z.output_nr) # 0其中,l知道是SumBackward0操作创建了l,并且SumBackward0节点知道节点AddBackward0创建了它的输入变量z,并且知道z是节点AddBackward0的第0个输入(通过调用z.output_nr),这创建了节点之间的一条边:(<AddBackward0 object at 0x7cf2f118c520>, 0)。
AccumulateGrad节点作为一个特殊的节点,负责接收和累计计算图中叶子变量x和y的梯度。
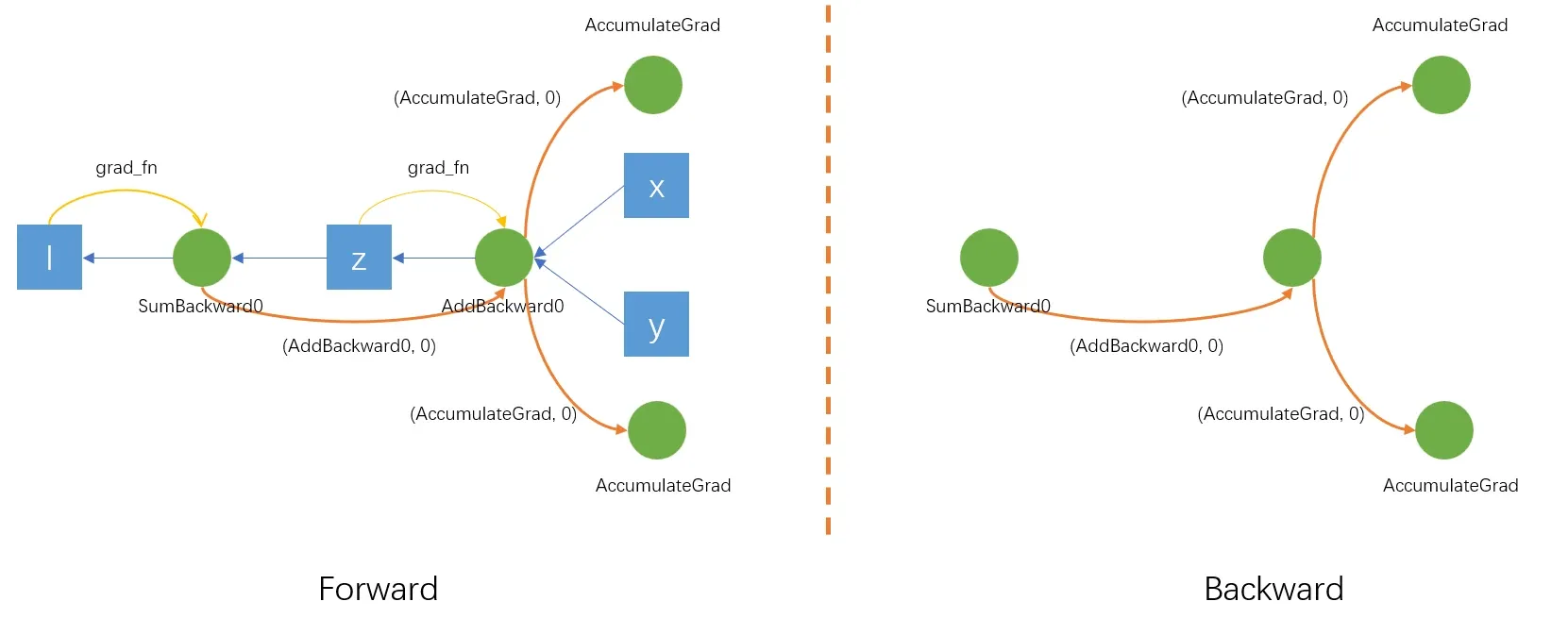
对于反向过程,对DAG图做拓扑序梯度累计和传播,具体地,每个节点都具有一个梯度槽,记录其节点的第个输出变量的梯度。当一个节点的全部输出的变量的梯度都被计算完毕之后,通过反向传播函数计算出输入变量的部分梯度和,遍历这个节点的边,对于第个边(next_node_i, output_nr),将next_node_i的第output_nr个梯度槽累加输入变量的部分梯度和。
一个简化版本的backward实现:
def backward(tensor):
que = Queue()
que.put(tensor.grad_fn) # 起点
while not que.empty(): # 拓扑序
current_node = que.get() # 取当前队首
grad_outputs = current_node.gradient_slots[:current_node.num_outputs] # 从梯度槽获得输出变量的梯度
grad_inputs = current_node.backward_fn(grad_outputs) # 计算反向传播函数,获得输入变量的部分梯度和
drop(current_node.gradient_slots[:current_node.num_outputs]) # 到这里就可以释放掉current_node节点的梯度槽了
for i, (prev_node, output_nr) in enumerate(current_node.next_functions): # 遍历边
prev_node.gradient_slots[output_nr] += grad_inputs[i] # 累加输入变量的部分梯度和(即链式法则)
prev_node.in_deg -= 1; # 减少入度
if prev_node.in_deg == 0: # 入度等于0,说明prev_node节点的输出变量的梯度已经全部累加完毕
# Pytorch在这里会执行Hook等函数,辅助实现一些功能(例如:DDP中梯度同步)
que.put(prev_node) # 放入队列
if retain_graph:
drop(current_node) # 释放节点current_node上的全部内存,包括其ctx上保存的输入,但是之后将无法再次调用backward!
下面是一个多变量输出节点的例子:
a = torch.randn(16, requires_grad= True)
x, y = a.split(8)
z = x + y
l = z.sum()
print(z.grad_fn.next_functions) # ((<SplitBackward0 object at 0x7c5dbd5a8580>, 0), (<SplitBackward0 object at 0x7c5dbd5a8580>, 1))下面是一个多路径累加梯度的例子:
x = torch.randn(16, requires_grad= True)
z = x + x
l = z.sum()
print(z.grad_fn.next_functions) # ((<AccumulateGrad object at 0x77be53783a30>, 0), (<AccumulateGrad object at 0x77be53783a30>, 0))感谢Pytorch的自动求导,如果我们想构建自己的算子,继承torch.autograd.Function然后定义forward和backward的计算即可,计算图Pytorch自动帮我们创建。
class MyFunc(torch.autograd.Function):
"""
C = A @ B
"""
@staticmethod
def forward(ctx, A, B):
ctx.save_for_backward(A, B)
return torch.matmul(A, B)
def backward(ctx, grad_output):
A, B = ctx.saved_tensors
grad_A = torch.matmul(grad_output, B.T)
grad_B = torch.matmul(A.T, grad_output)
return grad_A, grad_B相对于动态图,当然存在静态图,动态图是在前向计算的同时边计算边创建动态图连接,这种算子按惯例一般称为eager。静态图的前向过程则是只创建图不计算,具体过程一般是:
- 前向过程(只创建图不计算,有时候也称为符号计算symbolic)。
- 前向计算图优化(算子融合,加速器静态调度优化等)。
- 计算前向计算图。
- 计算反向梯度传播。
静态图相对于动态图,可以保存前向计算图(例如ONNX),这可以提供额外的优化,但实现起来要比直接动态图来说要复杂的很多,一般情况下动态图就足够了。
Megatron中的梯度求导与传播
模型定义
Megatron-LM的模型描述统一使用ModuleSpec管理,本文以分析bert模型为例,讨论Megatron-LM模型在训练过程中梯度求导、状态更新的底层原理。
bert_layer_local_spec = ModuleSpec(
module=TransformerLayer,
submodules=TransformerLayerSubmodules(
input_layernorm=LNImpl,
# Attention 实现
self_attention=ModuleSpec(
module=SelfAttention,
params={"attn_mask_type": AttnMaskType.padding},
submodules=SelfAttentionSubmodules(
linear_qkv=ColumnParallelLinear,
core_attention=DotProductAttention,
linear_proj=RowParallelLinear,
q_layernorm=IdentityOp,
k_layernorm=IdentityOp,
),
),
self_attn_bda=get_bias_dropout_add,
# LayerNorm 实现
pre_mlp_layernorm=LNImpl,
# MLP 实现
mlp=ModuleSpec(
module=MLP,
submodules=MLPSubmodules(linear_fc1=ColumnParallelLinear, linear_fc2=RowParallelLinear),
),
mlp_bda=get_bias_dropout_add,
sharded_state_dict_keys_map={
"input_layernorm.": "self_attention.linear_qkv.layer_norm_",
"pre_mlp_layernorm.": "mlp.linear_fc1.layer_norm_",
},
),
)
MLP 层
megatron/core/transformer/mlp.py
bert模型在Megatron-LM中的定义如下,其实还有一个使用transformer_engine库版本的,本文使用megatron core版本的标准bert模型进行讨论。
mlp=ModuleSpec(
module=MLP,
submodules=MLPSubmodules(linear_fc1=ColumnParallelLinear, linear_fc2=RowParallelLinear),
)Megatron-LM的bert在MLP中定义了两个线性层,分别是linear_fc1和linear_fc2,类型分别是ColumnParallelLinear和RowParallelLinear,(为什么分别是这两个,后文会提到),这两个类是Megatron-LM的TP (Tensor Parallel) 中的核心实现,实现了线性层如何进行TP并行推理和训练。
RowParallelLinear
线性层的定义是 ,其中为输入,为权重矩阵,是偏置,为输出。Megatron-LM的RowParallelLinear的切分矩阵的方法是:
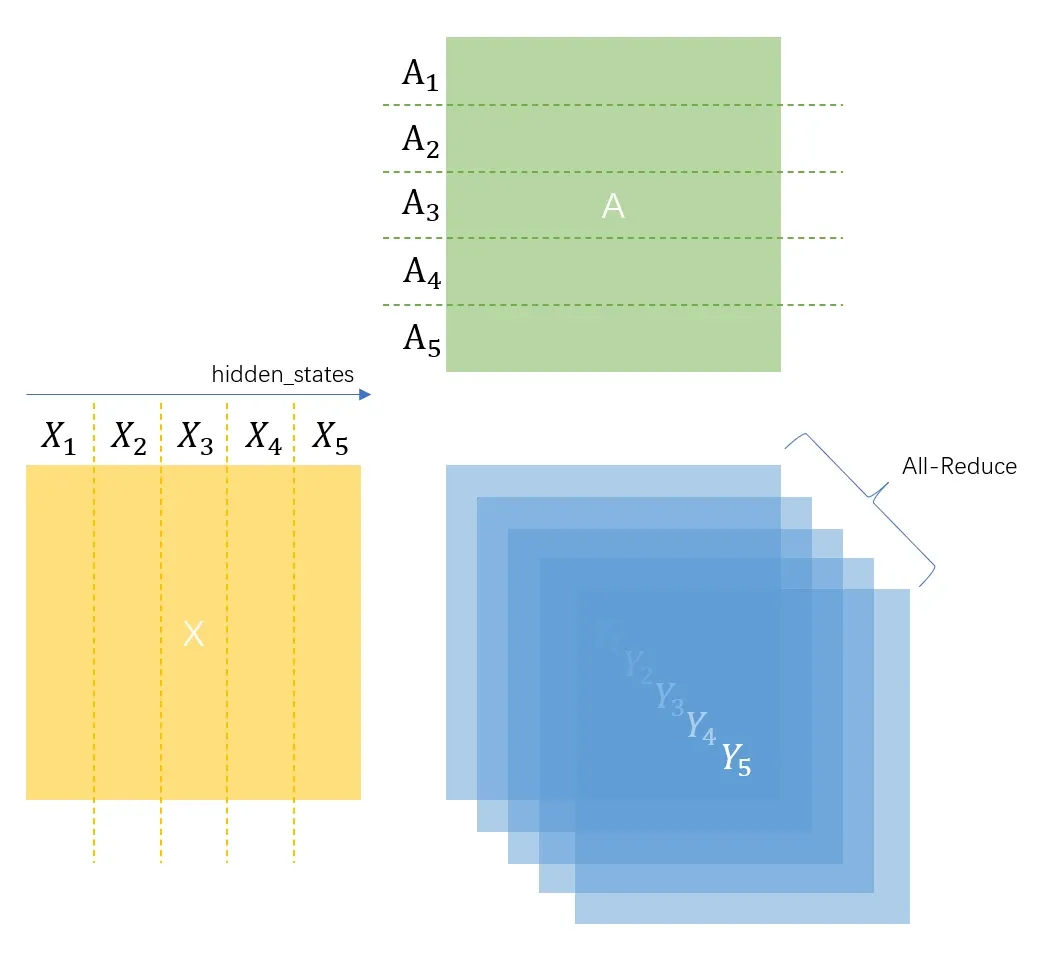
这样每个GPU上只需要保存一份即可,RowParallelLinear的weight定义代码如下:
self.weight = Parameter(
torch.empty(
self.output_size,
self.input_size_per_partition, # 对A做了分块处理,每个GPU只管理自己的A_i
device=torch.cuda.current_device(),
dtype=config.params_dtype,
)
)然而在RowParallelLinear中bias是不做TP并行的,每一个GPU都需要存一个相同的bias,bias定义如下:
self.bias = Parameter(
torch.empty(
self.output_size, # 不并行
device=torch.cuda.current_device(),
dtype=config.params_dtype,
)
)forward定义了RowParallelLinear前向过程:
def forward(self, input_: torch.Tensor) -> tuple[torch.Tensor, torch.Tensor]:
"""Forward of RowParallelLinear
Args:
input_: 3D tensor whose order of dimension is [sequence, batch, hidden]
Returns:
- output
- bias
"""
# 切分X,获得自己块的X_i
input_parallel = scatter_to_tensor_model_parallel_region(input_, group=self.tp_group)
# 计算矩阵乘法Y_i = X_i @ A_i
output_parallel = self._forward_impl(
input=input_parallel,
weight=self.weight,
bias=None,
gradient_accumulation_fusion=self.gradient_accumulation_fusion,
allreduce_dgrad=allreduce_dgrad,
sequence_parallel=False,
tp_group=None,
grad_output_buffer=None,
)
# Reduce合并Y_i
output_ = reduce_from_tensor_model_parallel_region(output_parallel, group=self.tp_group)
# 根据需要,加上bias
output = output_ + self.bias
return output其中scatter_to_tensor_model_parallel_region方法切分的时候,最终调用的是tensor_list = torch.split(tensor, last_dim_size, dim=last_dim)方法沿最后一个维度即hidden维度进行切分。而reduce_from_tensor_model_parallel_region方法合并的时候,最终将调用torch.distributed.all_reduce(input_.contiguous(), group=group)方法进行合并。
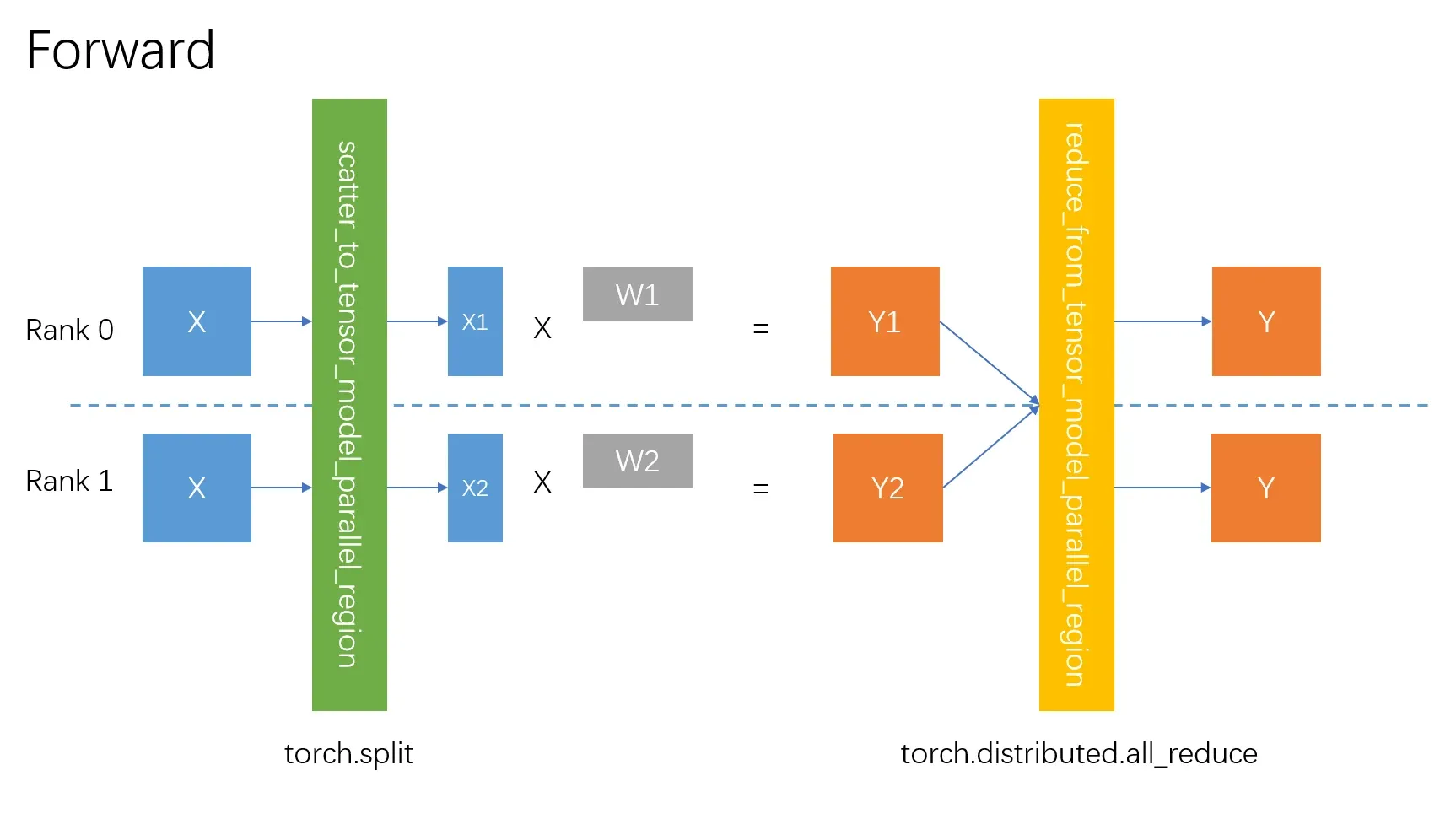
需要注意的是Forward过程中切分不需要做通讯,只需要切分,拿到属于自己的那个即可,因为调用forward方法之前,完整的就已经存在每个GPU上了。
通过Forward过程可以反推出Backward过程:
torch.distributed.all_reduce本质上矩阵加法,那么梯度的传播和矩阵加法的传播相同。
矩阵加法梯度计算: 对应的Jacobian矩阵为单位矩阵,因此直接返回梯度即可。
具体实现:
@staticmethod
def backward(ctx, grad_output):
"""Backward function."""
return grad_output_forward_impl是一个矩阵乘法实现,按照矩阵乘法的梯度传播计算即可。
矩阵乘法梯度计算: 推导过程太过枯燥,这里直接给出结论,令:
具体实现:
@staticmethod
def backward(ctx, grad_output):
grad_input = grad_output.matmul(weight)
grad_weight = grad_output.t().matmul(total_input)
grad_bias = grad_output.sum(dim=0)
return grad_input, grad_weight, grad_bias注意实际的是一个被广播的向量,所以这里需要对grad_output求和(链式法则,多路径)。
torch.split的反向求导即为拼接,这里的最终会调用torch.distributed.all_gather_into_tensor来拼接的梯度。
那么RowParallelLinear的反向梯度传播的过程总结为下图:
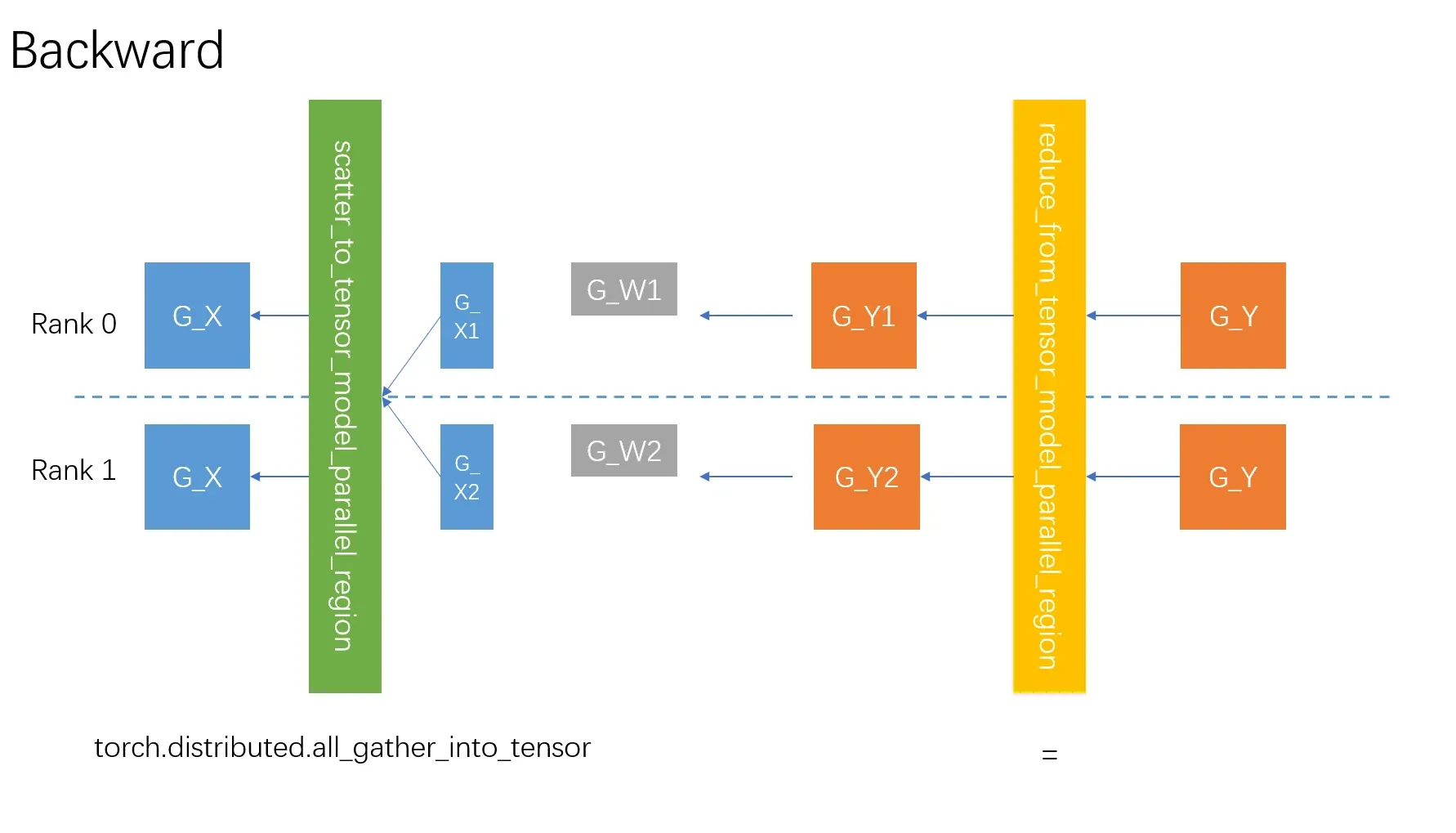
| 过程 | 通讯 | 参数量 | 瓶颈分析 |
|---|---|---|---|
| 前向过程 | all_reduce | [sequence, batch, output_dim] | 由于output_dim一般比较大,约等于input_dim,相对于对一个完整的大矩阵进行all_reduce |
| 反向过程 | all_gather_into_tensor | [sequence, batch, input_partition_dim] | 若TP足够大,input_partition_dim远小于output_dim,反向过程要快于前向过程 |
ColumnParallelLinear
ColumnParallelLinear将矩阵纵切,而不切,对计算得到的进行拼接。
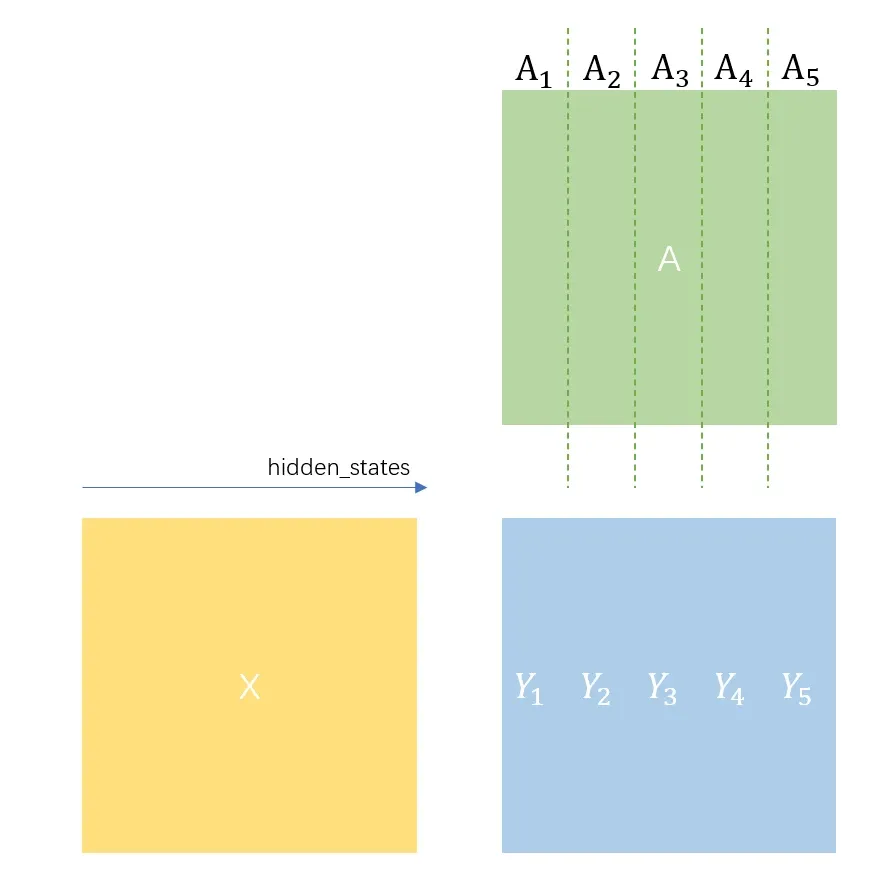
权重定义:
self.weight = Parameter(
torch.empty(
self.output_size_per_partition, # 纵切
self.input_size,
device=torch.cuda.current_device(),
dtype=config.params_dtype,
)
)注意ColumnParallelLinear的bias是分块的:
self.bias = Parameter(
torch.empty(
self.output_size_per_partition, # 分块
device=torch.cuda.current_device(),
dtype=config.params_dtype,
)
)前向过程:
def forward(
self,
input_: torch.Tensor,
weight: Optional[torch.Tensor] = None,
runtime_gather_output: Optional[bool] = None,
) -> Tuple[torch.Tensor, Optional[torch.Tensor]]:
"""Forward of ColumnParallelLinear
Args:
input_:
3D tensor whose order of dimension is [sequence, batch, hidden]
weight (optional):
weight tensor to use, compulsory when skip_weight_param_allocation is True.
runtime_gather_output (bool): Gather output at runtime. Default None means
`gather_output` arg in the constructor will be used.
Returns:
- output
- bias
"""
input_parallel = copy_to_tensor_model_parallel_region(input_, group=self.tp_group) # 其实就是直接返回input_
# 矩阵乘法
output_parallel = self._forward_impl(
input=input_parallel,
weight=weight,
bias=bias,
gradient_accumulation_fusion=self.gradient_accumulation_fusion,
allreduce_dgrad=allreduce_dgrad,
sequence_parallel=False if self.explicit_expert_comm else self.sequence_parallel,
grad_output_buffer=(
self.grad_output_buffer if self.config.defer_embedding_wgrad_compute else None
),
wgrad_deferral_limit=(
self.config.wgrad_deferral_limit
if self.config.defer_embedding_wgrad_compute
else None
),
tp_group=self.tp_group,
)
# torch.distributed.all_gather_into_tensor
output = gather_from_tensor_model_parallel_region(output_parallel, group=self.tp_group)
return output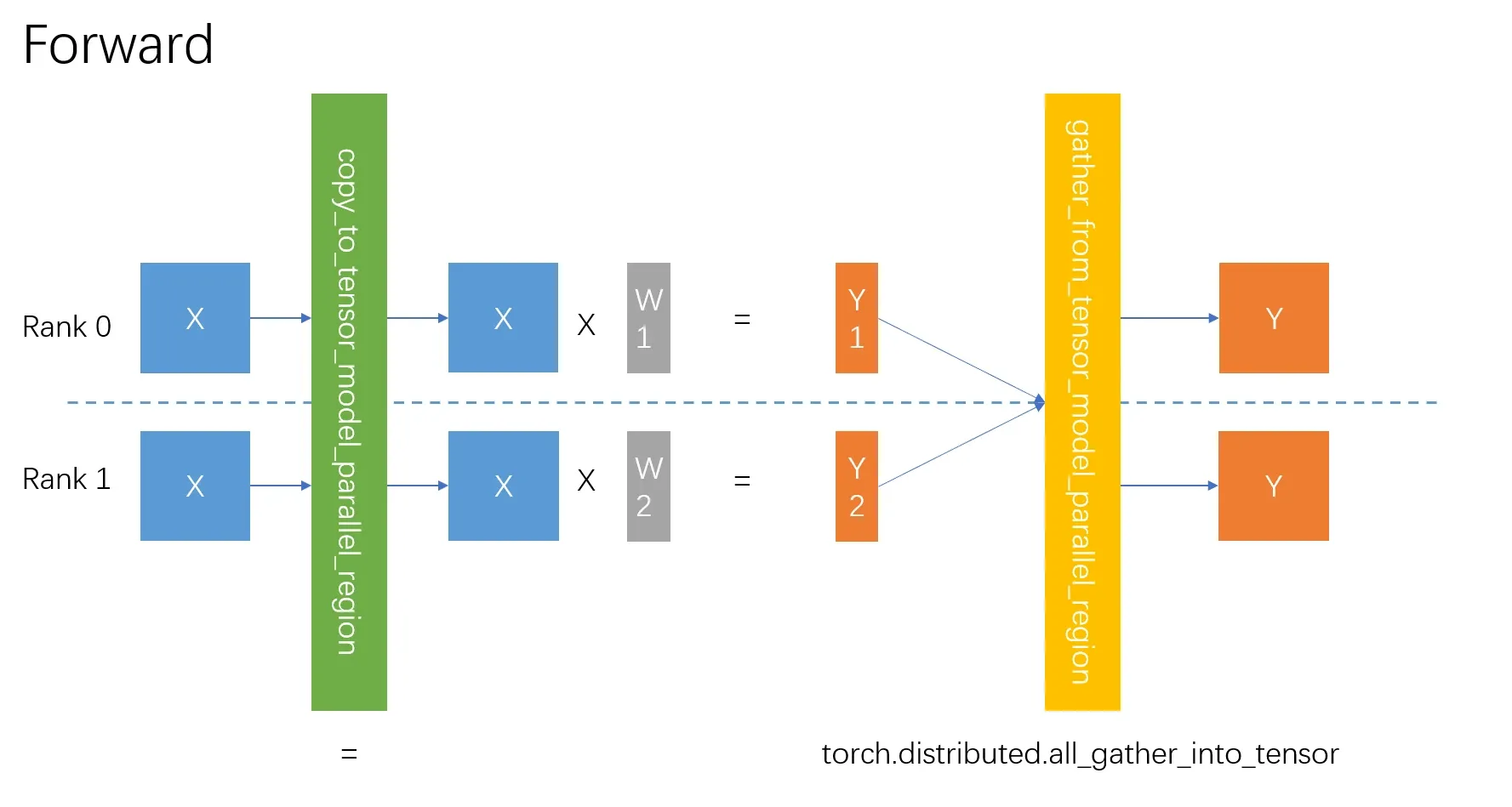
反向过程:
copy_to_tensor_model_parallel_region相当于一个恒等拷贝函数,反向则是要all_reduce(链式法则,多路径)。- 矩阵乘法,上面分析过了,此处不再赘述。
gather_from_tensor_model_parallel_region反向则是要split。
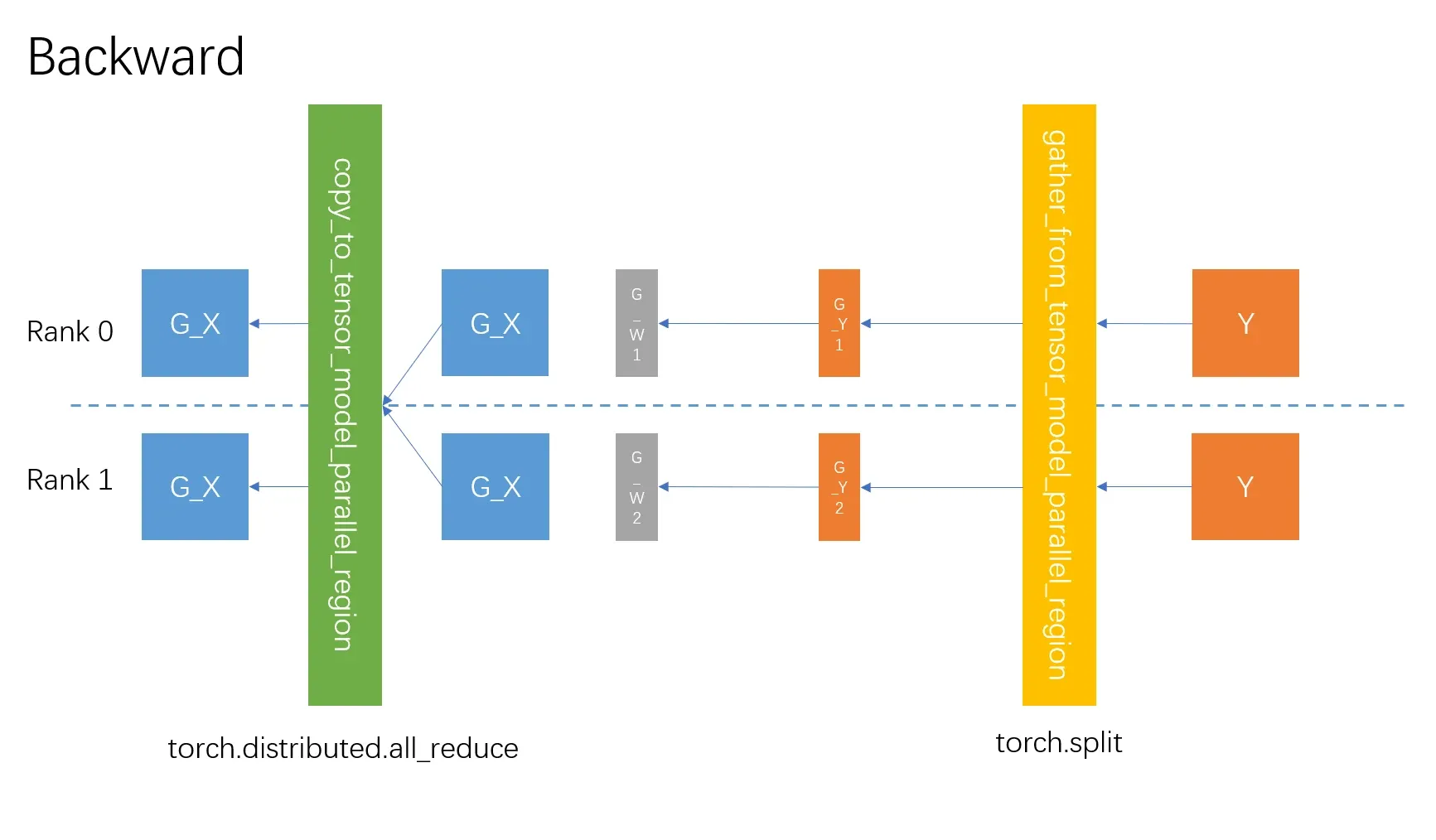
| 过程 | 通讯 | 参数量 | 瓶颈分析 |
|---|---|---|---|
| 前向过程 | all_gather_into_tensor | [sequence, batch, output_partition_dim] | 若TP足够大,output_partition_dim较小,前向过程速度较快 |
| 反向过程 | all_reduce | [sequence, batch, input_dim] | input_dim比较大,因此反向过程速度慢 |
重要结论:output_dim大的input_dim小的(up projection层)用ColumnParallelLinear,反之(down projection层)用RowParallelLinear,将获得最大计算通讯比。
激活函数
Megatron-LM没有对激活函数做什么文章,一般就是使用TE的或者直接用pytorch提供的,例如torch.nn.functional.gelu。
激活函数一般是标量函数,按照标量函数求导即可。
LayerNorm
Megatron-LM支持Apex的LayerNorm和pytorch的LayerNorm,我们以pytorch的torch.nn.LayerNorm为例分析LayerNorm的梯度计算问题。
LayerNorm对输入激活值,分别做LayerNorm,不失一般性,我们考虑一个Token的情况,即,是隐藏状态的大小。
正向过程:
- 求均值和方差:
- 去输入的中心化和归一化尺度
- 重新引入当前层的中心化的缩放尺度
其中和是可以学习的参数。
反向过程:
令。
- 仿射变换的梯度
- 归一化梯度
从归一化公式:
因为和来源于全体,因此单个的梯度需要传回给整个,我们记的梯度为,那么:
进一步可以改成向量的形式:
减去两个向量方向上的投影分量,可以发现和和正交,去掉了两个无用的方向:
- ,表示均值方向,SGD中不会改变的均值,因为改变了LayerNorm也会去均值,这是一个无用方向。
- ,表示缩放方向,SGD中不会改变的缩放(方差),因为改变了LayerNorm也会强制令方差为1,这也是一个无用方向。
RMSNorm
RMSNorm是当前LLM常用的Norm方法。在Transformer中,“平移不变性(shift invariance)大多是冗余的”,真正关键的是“尺度控制(scale control)”。
因此RMSNorm去掉了LayerNorm的均值计算:
Post-Norm 还是 Pre-Norm
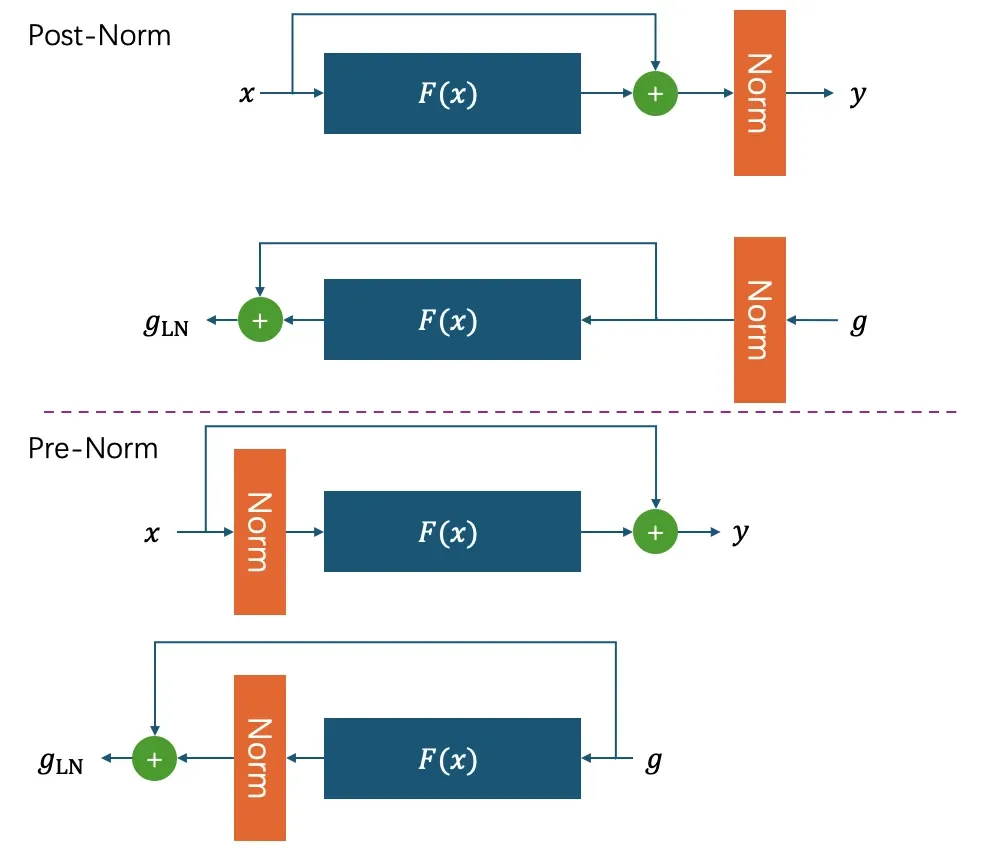
从下面的图片,可以发现Post-Norm中残差可以正常传播,但是梯度却需要先经过Norm之后才算残差,那就不对称了。但是Pre-Norm的的残差可以正常计算。因此当今LLM用Pre-Norm比较多。
Embedding
Embedding本质是一个查表矩阵,如果将输入转换成one-hot格式的矩阵,那么Embedding本质上还是矩阵相乘。假设loss对 embedding输出的梯度是,那么:
Megatron-LM,提供了一种并行查表机制:tensor_parallel.VocabParallelEmbedding。
Dropout
Megatron-LM使用pytorch的Dropout,即torch.nn.Dropout。前向过程为:
其中。
反向过程为:
Attention 层
megatron/core/transformer/attention.py
在Megatron-LM中,bert的Attention层定义为:
self_attention=ModuleSpec(
module=SelfAttention,
params={"attn_mask_type": AttnMaskType.padding},
submodules=SelfAttentionSubmodules(
linear_qkv=ColumnParallelLinear,
core_attention=DotProductAttention,
linear_proj=RowParallelLinear,
q_layernorm=IdentityOp,
k_layernorm=IdentityOp,
),
)其中qkv矩阵本质是一个向上投影操作,用ColumnParallelLinear,向下投影linear_proj用RowParallelLinear,前文MLP已经介绍过了,在此不再赘述。
大部分计算依旧是矩阵乘法,关于矩阵乘法的梯度传播在此不再赘述。我们重点关注Attention中Softmax的梯度计算。
在 Attention 里:
所以(省略了数学推导):
具体怎么高效实现可以看Flash-Attention的实现。
优化器
SGD
- 基础SGD
其中为第步的参数,为学习率,。
该优化器除了学习率这个标量参数,什么状态都不需要存。
在当前点做微小扰动,然后对损失函数做一阶泰勒展开:
SGD选择:
带入:
只要学习率,梯度不为,就有:
- Weight decay (L2 正则)
有时候SGD会让某些参数变得超级大,这不利于网络收敛,因此希望通过加入参数L2正则项的损失函数惩罚那些超级大的参数:
对参数求导:
这等价于在上加入一个:
整理:
每一步都会近似指数下降,因此称为Weight decay。
相比基础SGD,多存了一个参数。
- Momentum
对每个参数引入速度变量:
你可以叫他:
- 惯性,动量(物理学)
- 滤波(信号与系统)
- 指数加权移动平均(数列)
相比基础SGD,每个参数都要多存一个,显存需求2W。
- Dampening
相比Momentum多了一个加权系数(1 - d)。
- Nesterov Momentum
相比Momentum用直接修正,Nesterov Momentum用先修正,然后再修正。
Adam
SGD中的所有参数的学习率是固定的,然而固定的学习率不一定适合所有参数,例如,在统一学习率:
- 有的参数梯度很大,这个步长=学习率X梯度,对他来说可能太大 -> 震荡。
- 有的参数梯度很小,这个步长对他来说可能太小 -> 几乎不学习。
本质原因就是:每个参数的尺度和学习率的尺度不匹配。
Adam提出将参数的梯度进行归一化到单位尺度,然后学习率也使用单位尺度,这样就解决了这个问题。
将参数的梯度视为一个随机变量,怎么在统计意义上把他归一化到单位尺度上呢?仿照对向量归一化,我们希望用其“典型方向”(一阶矩)除以“典型幅度”(二阶矩的平方根)来得到归一化的更新方向:
并且Adam同样使用指数移动平均估计的一阶矩和二阶矩:
这样我们就得到了Adam的参数更新公式:
可以在数学上证明:
用:
除此之外,当时和初始值会过小,Adam进行了修正:
当刚开始训练的时候,会放大和,当变的足够大的时候,,。
最终的Adam公式:
用于防止除以0。
最后,Adam的显存需求是3W。
AdamW
如果要把Weight decay和Adam结合起来一起用:
后面Adam把归一化到单位尺度,同时把也归一化到单位尺度上了,这样Weight decay的在上的效果就大大减弱了,AdamW希望Weight decay能独立于Adam。
AdamW把单独拿出来:
Megatron-LM中的优化器实现
megatron/core/optimizer
Megatron-LM的优化器参数由OptimizerConfig类描述,分别提供了两个子类AdamOptimizerConfig和SGDOptimizerConfig。
Megetron-LM Model的切分方式
一个Model按层被横向切分,称为Pipeline Parallel。之后又被纵向切分,称为Tensor Parallel。经过这两次切分得到的块被称为Model Chunk。
如果没开启VP(Virtual pipeline)一个Proc即负责一个Model Chunk,如果开启了VP,那么一个Proc需要负责多个Pipeline的阶段,即需要负责多个Model Chunk。
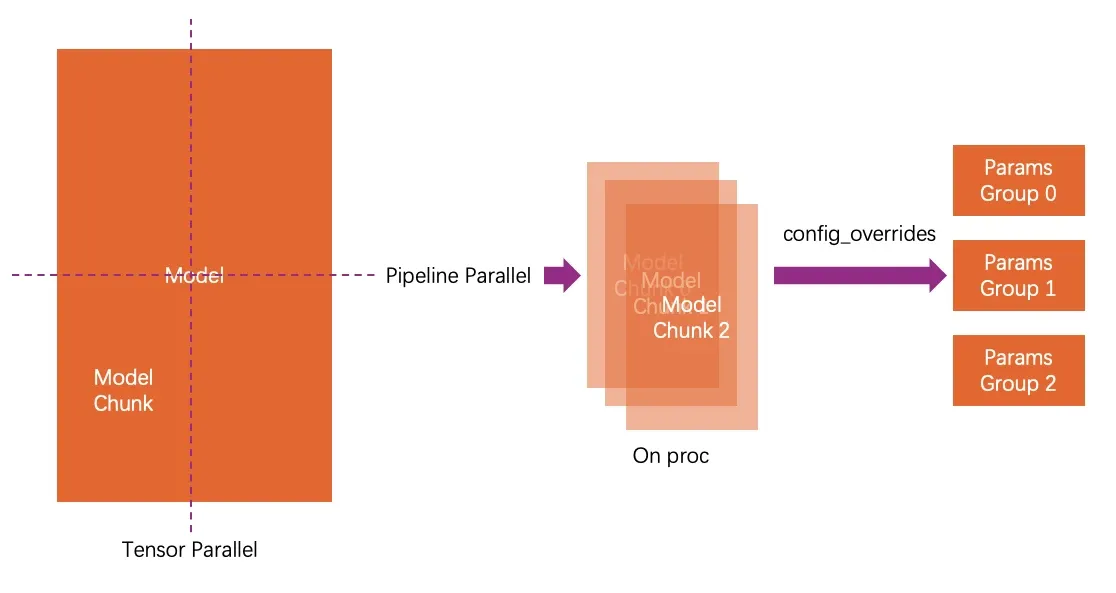
其中,Megetron-LM会在所有Model Chunk收集并按照具有相同优化器参数或策略配置的多个named_parameters打包成一个Param Group。
例如:
| 参数类型 | 处理方式 |
|---|---|
| bias | 不做Weight decay |
| weight | 做Weight decay |
| embedding | 特殊 lr |
| output head | lr decay 或放大 |
| MoE expert | 单独通信/更新 |
Megatron-LM会调用get_megatron_optimizer方法为当前设备上的model_chunks创建一个优化器。
def get_megatron_optimizer(
config: OptimizerConfig, # 这里保存了优化器参数
model_chunks: List[MegatronModule], # get_model方法获得的当前设备上的model_chunks
config_overrides: Optional[Dict[ParamKey, ParamGroupOverride]] = None,
use_gloo_process_groups: bool = True,
pg_collection: Optional[ProcessGroupCollection] = None,
dump_param_to_param_group_map: Optional[str] = None,
) -> MegatronOptimizer:
"""Retrieve the Megatron optimizer for model chunks.
We use separate optimizers for expert parameters and non-expert parameters.
Args:
config (OptimizerConfig): optimizer configuration object.
model_chunks (List[MegatronModule]): model chunks to get optimizer for.
config_overrides (Optional[Dict[ParamKey, OptimizerConfig]]): optional dictionary of
optimizer configuration objects to override default optimizer behavior for different
subsets of parameters (identified by ParamKey).
use_gloo_process_groups (bool): if false, disable use of Gloo process groups
in underlying Megatron optimizers.
pg_collection: Optional unified process group for distributed training.
dump_param_to_param_group_map (Optional[str]): path to dump parameter to param group map.
Returns:
Instance of MegatronOptimizer.
"""
# 对model_chunks创建param_groups
param_groups, buffers = _get_param_groups_and_buffers(
model_chunks,
model_chunk_offset=model_chunk_offset,
config=config,
config_overrides=config_overrides,
filter_fn=lambda g: not g['is_expert_parallel'],
buffer_name='buffers',
)
optimizers = []
optimizers.append(
_get_megatron_optimizer_based_on_param_groups( # 底层返回一个实际的优化器实现,例如torch.optim.AdamW
config=config,
model_chunks=model_chunks,
param_groups=param_groups,
per_model_buffers=buffers,
model_parallel_group=mp_group,
data_parallel_group=intra_dp_cp_group,
data_parallel_group_gloo=intra_dp_cp_group_gloo,
data_parallel_group_idx=model_parallel_rank,
intra_dist_opt_group=intra_dist_opt_group,
distributed_optimizer_instance_id=distributed_optimizer_instance_id,
pg_collection=pg_collection,
)
return ChainedOptimizer(optimizers)
)
Megatron优化器的装饰器
Megatron的_get_megatron_optimizer_based_on_param_groups方法并不是之间返回底层优化器实例,例如torch.optim.AdamW,而是返回一个基类为MegatronOptimizer的装饰器实例,MegatronOptimizer为Megatron的额外功能提供了支持。
一般情况下Megatron-LM的step分为两个阶段:
- prepare_grads:做梯度准备,例如收集梯度,梯度剪裁,混合精度类型转换、缩放等都在这里完成。
- step:真正的优化器算法更新部分。
基类MegatronOptimizer提供的主要公共功能有:
clip_grad_norm梯度剪裁
将一组梯度看成一个向量,然后求这个向量p-范数,如果很大,说明更新很大,设定一个max_norm参数,将缩放到max_norm。
一般我们使用L2 Norm,第一步计算clip_coeff:
第二步让每个都乘以。
注意和Adam的区别,同样是缩放梯度,Adam对历史平均梯度进行缩放,而梯度剪裁对瞬时梯度缩放,可以理解为Adam只能实现保持一个稳定的平均车速,而梯度剪裁避免一个突然的瞬时加速。
混合精度优化器
如果为优化器开启了混合精度优化器,Megatron的_get_megatron_optimizer_based_on_param_groups方法会返回一个优化器的混合精度装饰器。
FP32Optimizer
其step实现为:
@torch.no_grad()
def step(self):
"""Clip gradients (if needed) and step the base optimizer.
Always return successful since there is no overflow."""
# 准备梯度
self.prepare_grads()
# 梯度剪裁
# Clip gradients.
grad_norm = None
if self.config.clip_grad > 0.0:
grad_norm = self.clip_grad_norm(self.config.clip_grad)
# 实际的step
# 内部实际调用self.optimizer.step()
success = self.step_with_ready_grads()其prepare_grads实现为:
@torch.no_grad()
def prepare_grads(self):
for param_group in self.optimizer.param_groups:
for param in param_group['params']:
if hasattr(param, 'main_grad'):
param.grad = param.main_grad # 不做任何转换实际上FP32Optimizer是一个Dummy实现,没有增加额外的功能,具体还是依靠其装饰的self.optimizer.step()实现。
MixedPrecisionOptimizer
MixedPrecisionOptimizer 是所有混合精度优化器的基类,提供了从FP16梯度计算,更新参数的优化器实现。
Megatron-LM的混合精度训练
注意缩放发生在Loss和Grad上,因为Grad数量级较小如果直接用FP16运算会直接向下舍入到0。
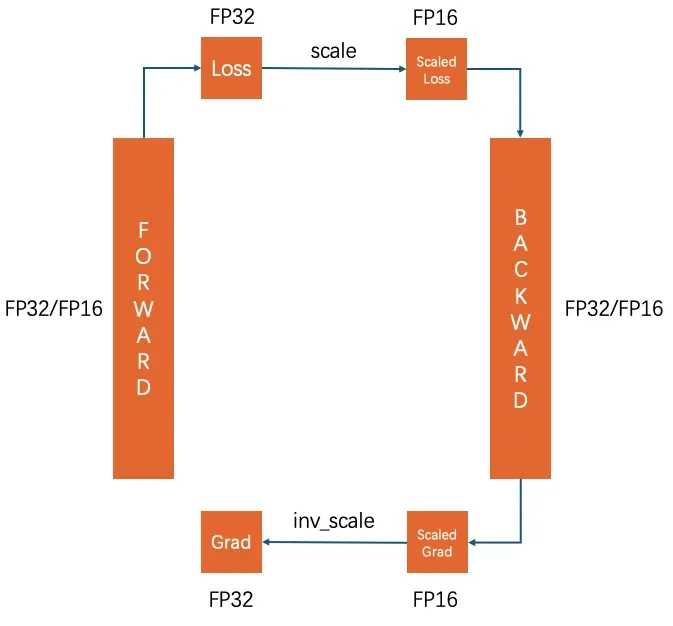
MixedPrecisionOptimizer在prepare_grads阶段:
@torch.no_grad()
def prepare_grads(self):
# 调用子类的_copy_model_grads_to_main_grads,这个方法是实现梯度浮点精度转换的核心,即FP16梯度->FP32梯度
self._copy_model_grads_to_main_grads()
# 梯度乘以inv_scale
self._unscale_main_grads_and_check_for_nan()而对于step阶段:
@torch.no_grad()
def step(self):
# ... 公共step过程
# 调用子类的_copy_main_params_to_model_params,这个方法是实现参数浮点精度转换的核心,FP32参数->FP16参数
self._copy_main_params_to_model_params()Float16OptimizerWithFloat16Params
Float16OptimizerWithFloat16Params 提供了FP16混合精度更新的完整实现,继承自MixedPrecisionOptimizer。
我们先看他的__init__方法里面将参数分为了三个组:
self.float16_groups = []
self.fp32_from_float16_groups = []
self.fp32_from_fp32_groups = []
for i, param in enumerate(param_group['params']):
# 如果这是一个FP16的参数
if param.type() in ['torch.cuda.HalfTensor', 'torch.cuda.BFloat16Tensor']:
# 先把原始参数加入float16_groups组
float16_groups.append(param)
# 从原始参数拷贝出一份F32的参数
main_param = param.detach().clone().float()
# 让优化器用我们FP32的参数进行优化更新
param_group['params'][i] = main_param
# 关联FP32参数
param.main_param = main_param
# 拷贝得到的FP32参数放进fp32_from_float16_groups这个组里
fp32_from_float16_groups.append(main_param)
# 优化器状态也要跟着移动
if param in self.optimizer.state:
self.optimizer.state[main_param] = self.optimizer.state.pop(param)
# 如果这是一个FP32参数,直接放进fp32_from_fp32_groups
elif param.type() == 'torch.cuda.FloatTensor':
fp32_from_fp32_groups.append(param)
param_group['params'][i] = param梯度浮点类型的转换在_copy_model_grads_to_main_grads函数中:
def _copy_model_grads_to_main_grads(self):
for model_group, main_group in zip(self.float16_groups, self.fp32_from_float16_groups):
for model_param, main_param in zip(model_group, main_group):
# model_param.main_grad是我们在Backward阶段得到的FP16梯度,需要转换成FP32
main_param.grad = model_param.main_grad.float()
# 对原本就是FP32的参数,不做类型转换
for model_group in self.fp32_from_fp32_groups:
for model_param in model_group:
model_param.grad = model_param.main_grad参数浮点类型的转换在_copy_main_params_to_model_params函数中:
def _copy_main_params_to_model_params(self):
# 只需要将FP32的参数拷贝到FP16就行,注意这里不发生缩放
for model_group, main_group in zip(self.float16_groups, self.fp32_from_float16_groups):
for model_param, main_param in zip(model_group, main_group):
_multi_tensor_copy_this_to_that(
this=main_data, that=model_data, overflow_buf=self._dummy_overflow_buf
)注意:开启混合精度会增加参数的显存占用,因为需要单独保存一份FP32格式的参数用于优化器更新,但混合精度并不是为了“减少参数内存”,而是为了“加速计算 + 降低激活和通信成本”,而 FP32 main weights 是为了解决低精度更新带来的数值问题。
分布式优化器
Megatron-LM提供了一个分布式优化器的实现DistributedOptimizer,在Pytorch没有引入FSDP的时候用于开启ZeRO优化,继承自MixedPrecisionOptimizer。
如果启动了Megatron-LM的FSDP,那么就会绕过DistributedOptimizer的实现,实际上DistributedOptimizer主要是一些并行分片功能,本文不再展开。
调度器
StepLR
每隔固定step_size,将当前学习率乘以一个衰减因子,本质上指数衰减:
MultiStepLR
相比StepLR固定的step_size,用户可以指定milestones什么时候衰减。
ExponentialLR
连续指数衰减,相比StepLR,每次调用step都会衰减。
CosineAnnealingLR
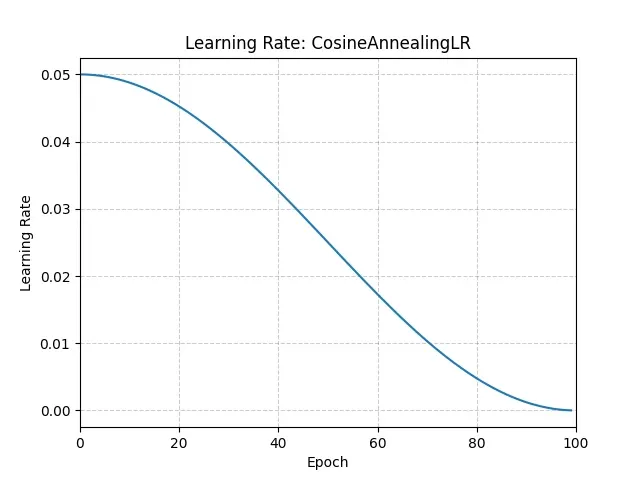
余弦退火,可以理解为先快慢下降,中间快,然后再慢。
CosineAnnealingWarmRestarts
也是余弦退火,但是带重启:
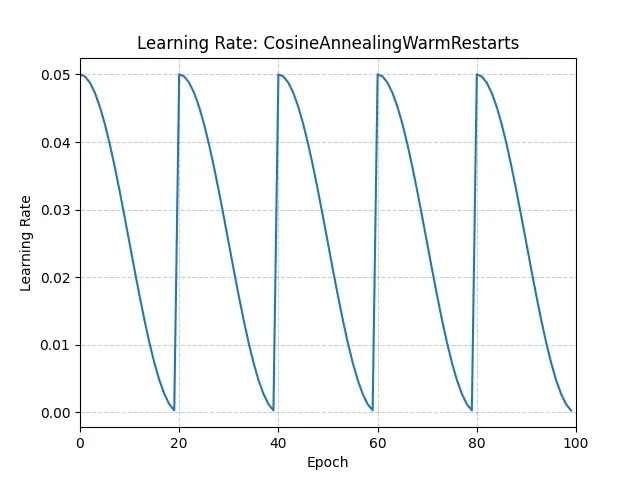
学习率周期性回到高点,有助于跳出局部最优。
LinearLR
线性升高LR:
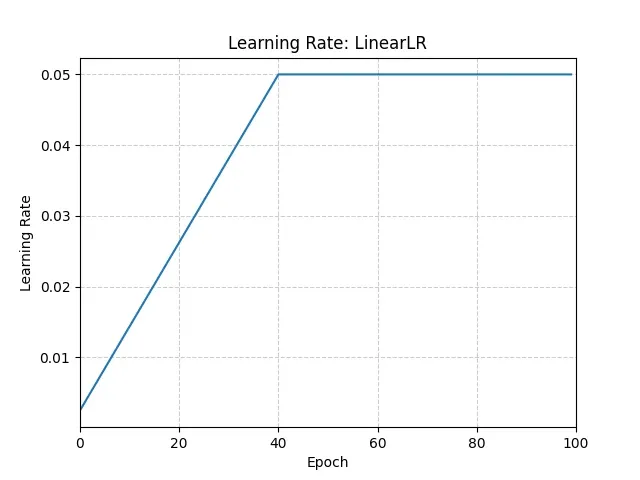
SequentialLR
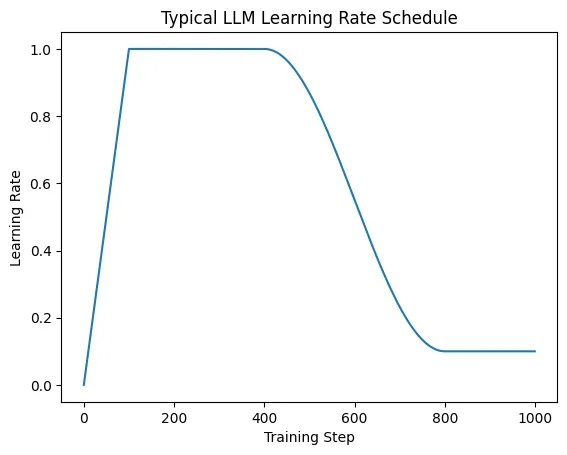
典型 LLM schedule:
- warmup(线性升高)
- 再 decay(cosine / linear)
这种情况下就可以用SequentialLR,把两个schedule组合起来。
LLM 常用策略
-
Linear Warmup + Cosine Decay:
- warmup steps: 1%–3%
- decay: cosine 到 0 或 min lr
-
Linear Warmup + Linear Decay
增加Warmup缓解了训练初期优化器状态估计不准,如果使用大学习率会梯度不稳的问题。
Megatron-LM中的调度器
Megatron-LM通过get_optimizer_param_scheduler创建一个调度器。最后返回一个OptimizerParamScheduler调度器。
def get_lr(self, param_group: dict) -> float:
"""Learning rate decay functions from:
https://openreview.net/pdf?id=BJYwwY9ll pg. 4
Args:
param_group (dict): parameter group from the optimizer.
"""
max_lr = param_group.get('max_lr', self.max_lr)
min_lr = param_group.get('min_lr', self.min_lr)
# 阶段1: Warmup
# 在Warmup阶段线性增长 init_lr -> max_lr
# Use linear warmup for the initial part.
if self.lr_warmup_steps > 0 and self.num_steps <= self.lr_warmup_steps:
return self.init_lr + (
(max_lr - self.init_lr) * float(self.num_steps) / float(self.lr_warmup_steps)
)
# 阶段2: Decay
# 如果是常数Decay,保持max_lr
# If the learning rate is constant, just return the initial value.
if self.lr_decay_style == 'constant':
return max_lr
# 阶段3: Tail
# 保持 min_lr
# For any steps larger than `self.lr_decay_steps`, use `min_lr`.
if self.num_steps > self.lr_decay_steps:
return min_lr
# 如果使用inverse-square-root,这是Attention is all you need那个论文提出的
# 但现在几乎不用了,因为余弦退火的效果比他好
# If we are done with the warmup period, use the decay style.
if self.lr_decay_style == 'inverse-square-root':
warmup_steps = max(self.lr_warmup_steps, 1)
num_steps = max(self.num_steps, 1)
lr = max_lr * warmup_steps**0.5 / (num_steps**0.5)
return max(min_lr, lr)
num_steps_ = self.num_steps - self.lr_warmup_steps
decay_steps_ = self.lr_decay_steps - self.lr_warmup_steps
decay_ratio = float(num_steps_) / float(decay_steps_)
assert decay_ratio >= 0.0
assert decay_ratio <= 1.0
delta_lr = max_lr - min_lr
coeff = None
# 线性Decay
if self.lr_decay_style == 'linear':
coeff = 1.0 - decay_ratio
# 余弦退火
elif self.lr_decay_style == 'cosine':
coeff = 0.5 * (math.cos(math.pi * decay_ratio) + 1.0)
# Weight-Stabilized Decay
# 先保持一段max_lr,然后在Decay
# 有时候也叫 late decay
elif self.lr_decay_style == 'WSD':
wsd_anneal_start_ = self.lr_decay_steps - self.wsd_decay_steps
if self.num_steps <= wsd_anneal_start_:
coeff = 1.0
else:
wsd_steps = self.num_steps - wsd_anneal_start_
wsd_decay_ratio = float(wsd_steps) / float(self.wsd_decay_steps)
if self.lr_wsd_decay_style == "linear":
coeff = 1.0 - wsd_decay_ratio
elif self.lr_wsd_decay_style == "cosine":
coeff = 0.5 * (math.cos(math.pi * wsd_decay_ratio) + 1.0)
elif self.lr_wsd_decay_style == "exponential":
coeff = (2.0 * math.pow(0.5, wsd_decay_ratio)) - 1.0
elif self.lr_wsd_decay_style == "minus_sqrt":
coeff = 1.0 - math.sqrt(wsd_decay_ratio)
else:
raise Exception(f'{self.lr_decay_style} decay style is not supported.')
assert coeff is not None
return min_lr + coeff * delta_lr另外Megatron-LM也对Weight decay系数做了调整:
def get_wd(self, param_group: Optional[dict] = None) -> float:
"""Weight decay incr functions
Args:
param_group (dict): parameter group from the optimizer."""
if param_group is not None:
start_wd = param_group.get('start_wd', self.start_wd)
end_wd = param_group.get('end_wd', self.end_wd)
else:
start_wd = self.start_wd
end_wd = self.end_wd
if self.num_steps > self.wd_incr_steps:
return end_wd
if self.wd_incr_style == 'constant':
assert start_wd == end_wd
return end_wd
incr_ratio = float(self.num_steps) / float(self.wd_incr_steps)
assert incr_ratio >= 0.0
assert incr_ratio <= 1.0
delta_wd = end_wd - start_wd
if self.wd_incr_style == 'linear':
coeff = incr_ratio
elif self.wd_incr_style == 'cosine':
coeff = 0.5 * (math.cos(math.pi * (1 - incr_ratio)) + 1.0)
else:
raise Exception(f'{self.wd_incr_style} weight decay increment style is not supported.')
return start_wd + coeff * delta_wd让Weight Decay系数先小后大的原因:
- 训练开始,允许某些参数快速更新,帮助模型快速收敛
- 训练末期,加重L2 正则,防止有些参数过拟合